Blog

Operations & Maintenance
Manufacturing Maintenance: Everything You Need to Know
Key Takeaways: The manufacturing industry relies heavily on a wide range of machinery and equipment, making maintenance an essential component of its operations. Safety, efficiency, and bottom lines take a significant hit when this is neglected. And yet, maintenance often doesn’t receive the attention it deserves, whether due to competing priorities or a lack of […]
Key Takeaways:
CMMS solutions help streamline and improve entire maintenance operations
A typical industrial business loses $125,000 an hour due to unplanned downtime
Due to labor shortages, maintenance personnel struggle to perform their tasks properly.
The manufacturing industry relies heavily on a wide range of machinery and equipment, making maintenance an essential component of its operations.
Safety, efficiency, and bottom lines take a significant hit when this is neglected.
And yet, maintenance often doesn't receive the attention it deserves, whether due to competing priorities or a lack of knowledge.
This article aims to address the latter.
On this page, you’ll find a detailed overview of everything you need to know about manufacturing maintenance: from the basics of different maintenance types to the latest technologies shaping the field.
Let’s get started.
How Manufacturing Maintenance Changed Through Times
In its early stages, maintenance was primarily corrective—focused on fixing problems as they arose.
This worked well for a time.
But then, significant historical events like the Industrial Revolution and World War II brought about new developments and inventions, changing our maintenance needs as well.
At that point, a more proactive approach was needed to prevent serious equipment damage before it impacted operations. This forever changed the way maintenance is perceived and performed.
In the 1980s, digitalization began to reshape manufacturing maintenance even further.
Many new technologies were introduced, and Computerized Maintenance Management Systems (CMMS) started gaining more traction.
Fast forward to today, and we can access technological solutions that our predecessors could never have imagined.
With sensors, data analytics, and the Internet of Things (IoT), we can create smart systems that can predict equipment failures before they even happen.
The timeline below illustrates the history of manufacturing maintenance from its inception to the present day.
Source: WorkTrek
So, in just a few short decades, manufacturing maintenance has grown from a simple “fix it when it breaks” mindset to a high-tech, data-driven field.
It’ll be exciting to see what else the future has in store.
Key Objectives of Maintenance in Manufacturing
Of course, the ultimate objective of maintenance is to save money in the long run.
However, this can be achieved by focusing on several specific goals.
First and foremost, maintenance aims to prevent costly, unplanned downtime.
When a key piece of equipment suddenly stops working, it costs you differently, from lost production time and increased labor costs to missed delivery deadlines.
A 2023 ABB survey revealed that an hour of unscheduled downtime costs a typical industrial business a shocking $125,000.
And even more shocking is that 69% of plants experience this problem at least once a month.
Illustration: WorkTrek / Data: ABB
This is where well-planned upkeep comes into play.
If routine tasks like lubrication, calibration, and inspection are performed regularly, minor problems will likely be caught and fixed before they snowball into severe operational disruptions.
Similarly, maintenance ensures that production capacities stay at optimal levels.
This is important because a decrease in production capacity can lead to unnecessary expenses, bottlenecks in productivity, and reduced profitability.
Fabio Camargo de Oliveira, Technical Assistance and Services Manager at Wenger, an industrial equipment supplier, illustrates the impact of this issue with an example:
For example, if an extruder in good condition that usually produces 10 tons per hour—consuming approximately 25 kw per ton, [suddenly starts to produce] 7 tons per hour—consuming 32 kw per ton—it will spend more electricity, water, and steam due to wear and difficulty in stabilization, ultimately producing less and decreasing the manufacturer’s profit.
The problem is that, unlike downtime, you may not immediately notice a slow decline in production capacity, but only when it’s already started to harm your bottom line.
However, with proper maintenance, this issue can be avoided entirely.
Beyond just keeping things running, maintenance also plays a role in ensuring a safe work environment. After all, properly maintained equipment is far less likely to malfunction and injure your employees.
This directly translates to fewer accidents and decreased costs associated with workers' compensation, insurance premiums, legal liabilities, and productivity losses.
Did you know that, in the manufacturing industry, an average of 67 days are lost per injury?
Illustration: WorkTrek / Data: Travelers
That’s more than two months of missed work—no small matter.
When you add potential lawsuits, reputational damage, and lowered worker morale, the costs of neglecting equipment safety quickly increase.
Overall, the role of maintenance is very multifaceted. Many people aren’t even aware of just how impactful it can be.
It isn’t only about fixing broken assets—far from it—but about building a solid foundation for safe, profitable, and efficient operations.
Types of Manufacturing Maintenance (And When to Use Each)
There are many different types of maintenance used in manufacturing, each with its advantages, disadvantages, and ideal use cases.
Corrective or reactive maintenance, as the name implies, focuses on fixing problems after they have already occurred.
It often gets criticized for being ineffective in the long term, but there is a time and place for it—especially with non-critical assets.
Preventive maintenance, on the other hand, is a more proactive strategy.
It prioritizes frequent cleaning, parts replacement, and similar tasks to prevent unexpected failures and keep operational disruptions minimal.
According to the 2024 MaintainX survey, this is currently the most popular approach to asset upkeep, with 87% of respondents reporting its active use.
Illustration: WorkTrek / Data: MaintainX
And why wouldn’t they?
It’s proven to minimize unplanned downtime, extend equipment lifespan, and keep operations running smoothly.
Condition-based maintenance is also proactive, but its implementation differs from a preventive strategy.
Preventive maintenance schedules tasks based on regular time intervals or usage (e.g., every three months, or after a certain number of operating hours).
On the other hand, condition-based focuses on servicing when particular indicators show signs of decreasing performance or potential failure.
This way, you’re only maintaining equipment when it’s actually needed and not just because the calendar says you should.
Another maintenance type that’s been gaining traction in manufacturing is predictive maintenance.
You can consider it the more advanced version of a condition-based method.
It uses data, various sensors, and analytical tools like machine learning to identify, detect, and predict equipment issues before they even occur.
Kevin Tucker, Advisory Practice Lead at the IT services and consulting company Info-Tech Research Group, explains why this is such a valuable addition to any upkeep plan.
Illustration: WorkTrek / Quote: Facility Executive
Lastly, Total Productive Maintenance (TPM) is the all-hands-on-deck approach that blends corrective, preventive, and predictive methods into one strategy.
The idea here is that everyone within the operations should take responsibility for daily service tasks, which helps detect problems earlier and reduces the likelihood of unplanned downtime.
Here’s a quick overview of all these types of maintenance:
Type
Pros
Cons
When to use
Corrective
No upfront maintenance costs and minimal planning
If certain issues are overlooked, it can lead to unplanned downtime and more long-term costs
For non-critical assets and when replacement parts are easily accessible and repairs can be made quickly
Preventive
Reduces the likelihood of unexpected equipment failure and increases equipment lifespan
Can lead to unnecessary maintenance and requires more manpower and resources for routine checks.
For critical equipment that would cause significant downtime if it failed
Condition-based
Helps in planning upkeep activities without disrupting production and avoiding unnecessary maintenance
High initial costs for equipment and sensors, as well as challenging data management
When equipment has fluctuating loads and operating conditions
Predictive
Reduces unnecessary maintenance by only performing maintenance when needed
High initial setup costs for sensors, monitoring equipment, and software.
Requires skilled personnel to analyze data and manage systems
For critical equipment where downtime is very costly and when the needed technology is readily available and feasible to implement
Total Productive Maintenance
Engages all employees, increasing accountability and leading to a culture of continuous improvement
Requires significant effort for training and a high level of commitment from all employees and management
Where the highest manufacturing standards and employee accountability are a priority
So, which strategy should you implement? Which one's the best?
The truth is, there is no one-size-fits-all solution.
Your choice of maintenance activities should be tailored to your organization's and equipment's specific needs.
In most cases, this means mixing and matching all of these approaches to create a maintenance plan that works for you.
Why Is Maintenance in the Manufacturing Industry So Challenging?
Any experienced manufacturing maintenance professional will tell you their job isn’t always easy.
In addition to being a complex process, maintenance is often faced with various outside challenges that make it even more difficult.
For starters, there's a significant shortage of skilled workers.
According to an UpKeep survey, 72% of companies anticipate maintenance staff shortages and related issues in 2024.
Illustration: WorkTrek / Data: UpKeep
The problem is that seasoned professionals are all retiring, but new talent is tough to come by.
At the same time, technology is evolving at lightning speed, and not everybody can keep up.
This leaves maintenance teams spread too thin, often without the expertise needed to maintain equipment properly.
But the problems don't stop there.
It's more than just people we're running short on; it's the tools, spare parts, and materials, too.
A Limble study shows that 34.1% of manufacturing and facility maintenance professionals consider supply chain issues one of their biggest challenges.
Illustration: WorkTrek / Data: Limble
This issue leads to delays in the delivery of spare parts, increased costs for specific items, and difficulties in accurately forecasting resource needs and managing inventory.
Consequently, organizations either face understocking, which causes delays, or overstocking, which ties up their cash flow and storage space.
Either way, the machinery doesn’t get the care it needs when needed, and productivity takes a hit.
And then there’s the budget—or lack thereof.
Many maintenance teams operate with minimal budgets, preventing them from doing their jobs properly.
This is because, for too many executives, strategic upkeep is an afterthought, overshadowed by short-term cost-cutting.
John Sedgwick, Director of Engineering and Maintenance at the chemical manufacturing company HEXPOL Compounding, experienced this first-hand.
Illustration: WorkTrek / Quote: Industry Week
His team initially had issues with productivity and unplanned downtime.
However, the situation improved once the company prioritized proper upkeep and invested more in maintenance software.
And it makes sense. Without adequate financial backing, maintenance always suffers.
Aging equipment isn’t replaced or upgraded, training or tech investments fall by the wayside, and teams are forced to rely solely on reactive maintenance.
Put simply, short-term savings lead to long-term problems.
All in all, with all these issues and more, it’s clear why maintenance in manufacturing is so challenging.
But what’s the solution?
How to Ensure Effective Manufacturing Maintenance
The answer to these challenges is clear: start prioritizing effective manufacturing maintenance.
Let’s dive a bit deeper into what that means, exactly.
It all begins with maintenance planning and then regularly updating the plan to reflect your changing needs.
This plan should clearly outline which assets need maintenance, the type of maintenance they require, how often, and who’s responsible for it.
Vivre Viitanen, Head of Global Service Line at ABB Motion Services, a technology leader in electrification and automation, outlines the benefits of having a well-structured plan:
When strategies are planned, you can ensure that the right capabilities and skilled people are in the right place at the right time and you have the necessary materials. That means the plan can be rolled-out in a more efficient and effective way than if you’re reacting to a situation which has come as a surprise or a shock.
In other words, a solid maintenance plan is the backbone of successful operations.
It prioritizes more strategic resource allocation and scheduling, boosting your processes' effectiveness.
To take it up a notch, create Standard Operating Procedures (SOPs) that go hand-in-hand with your plan.
SOPs are more granular, step-by-step instructions on executing specific tasks, in what order, and with which resources.
Source: FMX
This ensures more consistency in your practices, eliminating mistakes and confusion.
When everyone knows exactly how to fulfill their responsibilities, everything gets done on time, safely, and efficiently—every single time.
However, it’s not enough to simply tell your team what to do and how to do it.
You should also monitor performance to ensure your plans and procedures are effective and realistic.
For example, if you’re still struggling with high downtime rates despite careful planning, it’s a sign that something is off.
Maybe your instructions regarding a particular activity aren’t clear enough, or perhaps some equipment needs specialized maintenance that you didn’t account for.
Tracking relevant KPIs is the best way to gauge your performance.
These metrics provide clear, data-driven insights into the effectiveness of your upkeep efforts, without any biases or relying on guesswork.
After all, the numbers never lie.
Here are some KPIs worth considering:
Mean Time to Repair (MTTR)
Mean Time Between Failures (MTBF)
Overall Equipment Effectiveness (OEE)
Planned Maintenance Percentage (PMP)
And if you’d like to explore these metrics in more detail, check out our guide on the top 5 maintenance metrics you should always have in mind.
Overall, these practices are a solid starting point for more efficient maintenance operations.
Still, given the complexity of the process and the challenges involved, they may not be enough on their own.
Luckily, there are many digital tools available that can help further streamline and improve your maintenance efforts.
Modern Tech Used For Factory Maintenance
From advanced robots to augmented reality, a wave of exciting new technologies is transforming manufacturing maintenance.
One technology that has been in the spotlight for some time now is AI.
AI is a key component in predictive maintenance, where machine learning models analyze historical and real-time data to predict future equipment failures.
The technology becomes even more powerful when combined with IoT sensors.
Rakesh Prasad, Senior Vice President of Digital Business at Innover Digital, a technology and process digitization company, explains how this integration works:
For PdM, IoT sensors are fitted in machines and equipment to monitor their health and surroundings, gathering data on factors such as vibration, temperature, and humidity. This data is then relayed to a central system that employs AI/ML algorithms to examine the data and give insights into the equipment or machinery’s well-being.
With countless data points to draw from, AI-driven predictive maintenance can deliver precise forecasts.
This allows its users to schedule upkeep accurately and keep equipment in peak condition without over-maintenance.
Remote monitoring is another technology that is making significant strides in manufacturing maintenance.
It uses various sensors, software, and tools to detect and diagnose issues without requiring maintenance personnel to be physically present.
Robots and drones are increasingly being used for this purpose, too.
Jeff Burnstein, President of the Association for Advancing Automation, predicts we'll see even more robots used in this space.
Illustration: WorkTrek / Quote: Plant Services
With remote monitoring, you can access hard-to-reach areas and capture high-resolution images and videos.
This gives you a full 360-degree view of your equipment's health.
In other words, you get more data but fewer safety risks—a true win-win scenario.
The last type of tech on our list is a Computerized Maintenance Management System (CMMS), like our own WorkTrek.
You can think of this tool as your ultimate command center for the entire maintenance operation.
For those routine tasks, you can use WorkTrek’s task management feature to create and assign tasks, keep track of completed work, and see how much time your team spends on certain activities.
Source: WorkTrek
Plus, your staff can report problems and generate work requests by going through our web and mobile apps or via the WorkTrek Request portal.
You can create new work orders as soon as those requests come in and assign them to the right technician or team.
Source: WorkTrek
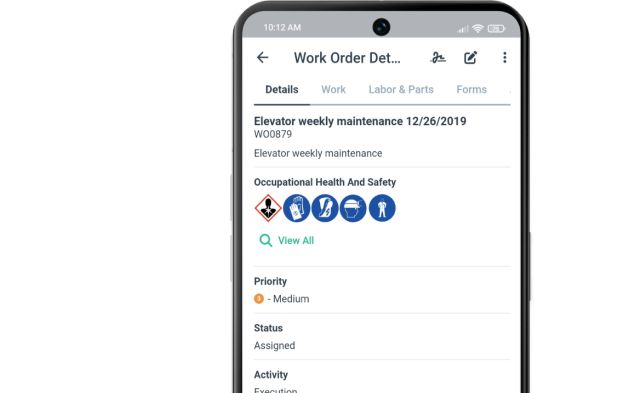
Each work order comes with all the details—priority level, needed resources, and more—so your team can get the job done right and on time.
But that’s not all.
With WorkTrek, you can keep a close eye on your inventory, tracking quantities, locations, and costs of your spare parts and materials.
Source: WorkTrek
The system enables you to specify minimum quantities for products and then alerts you when your inventory falls below a safe level so that you can restock on time.
It’s really easy to see why maintenance professionals love CMMS so much.
Thanks to this technology, you can manage your whole maintenance operation from a single, intuitive dashboard and, in turn, improve overall efficiency and save money.
Conclusion
Hopefully, you now see manufacturing maintenance for the vital process it truly is.
When done right, it can transform entire operations beyond recognition, boosting profitability, safety, and efficiency.
Plus, being a manufacturing maintenance professional has never been more exciting.
The field is full of new technologies that help simplify the complexities and tackle the challenges that usually come as a part of the job.
We can now predict equipment problems, automate repetitive tasks, and eliminate errors, all from our computers.
So don’t let anyone tell you maintenance is just another routine task when, in reality, it’s the backbone of any successful operation.

Operations & Maintenance
5 Tips for Efficient Maintenance Scheduling
Scheduling maintenance activities is a complex task, no doubt about it.
There are many factors to consider, from technician skills and availability to production schedules and the impact of downtime on your facility’s operations.
That is precisely why, in this article, we’re sharing our best tips to help you efficiently schedule maintenance tasks and keep your operations running smoothly.
Let’s get started.
Leverage Maintenance Management Software
The first thing you can do to schedule maintenance tasks more efficiently is to stop doing that manually.
Sure, using pen and paper—or perhaps Excel spreadsheets—for maintenance scheduling is inexpensive and straightforward since everyone is already familiar with these methods.
But is this truly the most efficient way to go about it?
Robert Burgh, President at Nexcor Food Safety Technologies, doesn’t think so.
He explains that using CMMS is the best way to schedule maintenance tasks.
Such software solutions, he says, make scheduling more efficient, as all the necessary data is aggregated and easily accessible in one place.
Illustration: WorkTrek / Quote: Food Safety Magazine
Using a CMMS means no more digging through paperwork to figure out when specific technicians are available or shuffling the entire schedule because you accidentally double-booked someone.
With all the relevant data in one central location, maintenance management becomes a breeze.
To illustrate our point, we’ll use our maintenance management software, WorkTrek, as an example.
Our Work Order Scheduler provides a holistic view of all things maintenance.
Source: WorkTrek
You can see which technicians are available, what maintenance tasks are assigned, and their status.
This makes it easier to create and assign new work orders.
What makes this system even better is that its benefits extend to your maintenance technicians.
Once assigned a work order, they’ll receive a notification via our mobile app.
Source: WorkTrek
That way, they don’t have to constantly check in with their supervisor to see whether there are any new tasks they’re in charge of.
They can access the app anywhere, anytime, and find out exactly what they need to do.
In addition, WorkTrek allows users to enrich work orders with details such as the start and end date, the description of the problem at hand, and instructions on how to fix it.
Source: WorkTrek
This minimizes the back-and-forth communication between technicians and supervisors as the software answers many potential questions.
In short, relying on CMMS streamlines a plethora of maintenance scheduling processes that are time-consuming and error-prone.
Does it require an initial investment and getting used to it? Yes.
But leveraging maintenance management software for this purpose will save you and your team so much time, energy, and money in the long run, so it pays off.
Match Technician’s Skills to Tasks
An important part of scheduling maintenance is ensuring that the technicians you choose to assign specific tasks have the necessary skill set to complete them.
That’s because accounting for skill levels when assigning tasks ensures each task is carried out correctly, efficiently, and safely.
If tasks are assigned to technicians who are not skilled enough to handle them, the consequences can be detrimental.
Take the 2020 Evergreen Packaging Paper Mill incident for example.
Source: CSB
In this tragic case, two Blastco workers were tasked with repairing the inside surface of the upflow tower using epoxy vinyl ester resin and fiberglass matting.
Since the night was colder, the resin—which hardens faster at higher temperatures—and fiberglass matting were not hardening at the expected rate.
After they couldn’t stop the material from sliding down the tower's walls, the workers used an electric heat gun to get the resin to harden.
The heat gun ended up falling into the bucket of flammable resin, causing a fire that traveled through the connecting pipe, ultimately killing the workers maintaining the downflow tower.
After the incident, the U.S. Chemical Safety Board (CSB) Lead Investigator Drew Sahli said:
Illustration: WorkTrek / Quote: USCSB on YouTube
Had the task been given to workers experienced with resin application in cold weather, this tragedy could have been prevented.
So, what can we learn from this?
For starters, this tragic incident underscores the importance of thoroughly evaluating the skills and experience of each technician before assigning them a maintenance task.
The research conducted by Plant Engineering has shown that over 70% of maintenance personnel in the facilities are trained in basic mechanical and electrical skills.
However, significantly fewer technicians have the skills necessary for maintaining fluid power systems, for instance.
Source: Plant Engineering
So, before you schedule any of your technicians for a task, try to determine whether they have the experience and certifications needed to perform it.
This is, again, where having a CMMS comes in handy.
As you can see in the screenshot below, you can use your CMMS to store information about any training courses your workers have completed and see what maintenance tasks they’ve handled in the past.
Source: WorkTrek
With this information at your fingertips, you can always be confident that the technicians you’re assigning tasks to can complete them.
Coordinate Maintenance Schedules with Operations
Yes, figuring out who you should assign to which maintenance task is essential.
However, another big question needs to be answered correctly to maintain the efficiency of your facility’s operations.
And that question is: “When is the best time to schedule specific maintenance tasks?”
As it turns out, answering it is not as easy as it may seem.
If it were, the results of the 2022 Maintenance Manager Report wouldn’t show that planning and scheduling maintenance are the biggest challenges for most maintenance teams.
Illustration: WorkTrek / Data: Add Energy
What makes scheduling maintenance so complex is that it involves more than simply matching tasks to the workers who can perform them.
For starters, if not properly scheduled, maintenance can throw off operations at your facility, causing disruptions and delays.
So, don’t schedule maintenance in a vacuum.
Instead, regularly meet and discuss maintenance with others, as this will give you a complete picture of your facility’s activities.
For instance, an operations manager might inform you that some production activities need to be completed by a specific date, so scheduling maintenance before then would throw a wrench in the works.
Or, a procurement officer could tell you that the spare parts your technicians will need for a specific maintenance task won’t be delivered as planned.
This kind of information can be a lifesaver when trying to create a solid schedule.
Aside from consulting with the stakeholders within your facility, you may also want to consider implementing predictive maintenance.
This approach to maintenance scheduling is all about using historical and real-time data and ML algorithms to predict future maintenance needs.
Hans Van der Aa, Senior VP of Lifecycle Services at the engineering and manufacturing company Duravant, finds that it can bring significant benefits to facilities trying to minimize unnecessary downtime caused by poor maintenance scheduling.
Illustration: WorkTrek / Quote: ProFood World
As you can see, multiple factors need to fall into place to develop the perfect maintenance schedule.
So, before you hastily assign work orders for the first available time slot, consider how your scheduling decisions will affect operations overall.
Whether this is through regular consultation with the key stakeholders, staying one step ahead by implementing predictive maintenance, or a combination of both, one thing is for sure.
Looking at the bigger picture will help you create a schedule supporting your facility’s overall goals.
Define How You Will Prioritize Maintenance Tasks
Not all maintenance tasks are equal.
You’ll probably agree that replacing a flickering lightbulb in the breakroom doesn’t carry the same weight as fixing a broken conveyor belt that has brought your production to a halt.
So, when scheduling maintenance activities, you need a clear idea of what constitutes an urgent task versus a non-critical one for your facility.
Ahmed Awad Ramadan, Maintenance Planning and Scheduling Department Manager at MIDOR Refinery explains how to do just that:
When it comes to work prioritization, we should consider two main criteria. First, the criticality of equipment, which reflects the effect of the asset's failure on the whole organization. Second, the nature of work. While equipment criticality is a fixed number and has to be aligned with the organization's strategy; the nature of work is variable and relies on the workers' perspective.
He explains that to assess the criticality of specific maintenance tasks, the Ranking Index for Maintenance Expenditures (RIME) is his tool of choice.
Illustration: WorkTrek / Quote: Click Maint
Observing the key components of RIME—criticality, cost impact, frequency of failure, and downtime—can help you gain clarity and decide which tasks should be tackled first.
For instance, repairing a machine that is critical to the operations, but has recently experienced more frequent issues is bound to take priority over a costly repair with barely any impact on the production.
Many maintenance professionals also like to use a scale from 1 to 5 to denote the criticality of maintenance tasks, where 1 is a low-priority task, and 5 is urgent work.
John Q. Todd, a senior business consultant and product researcher at Total Resource Management and a leading asset management solutions provider, shares an important insight regarding the use of this approach.
He says he had clients who’d gone as far as to use a scale from 1-10 for task prioritization, which ultimately rendered them unable to determine the actual difference between priority levels 4 and 5, for example.
Therefore, he explains, that keeping your priority scale small can significantly simplify the decision-making process.
Illustration: WorkTrek / Quote: LinkedIn
Many maintenance management systems have this priority scale feature, which makes assigning priority levels easier, as you can see in the example below.
Source: WorkTrek
This feature makes it easier for you to assign tasks and allocate resources for maximum operational efficiency.
It also helps your maintenance technicians understand the importance and urgency of each task they’ve been assigned.
On a particularly busy day, for instance, knowing how high of a priority each task on their list is can help them make sure that they tackle those critical ones first.
So, before you put any maintenance tasks into the schedule, determine exactly how you will prioritize them.
Use Past Job Data to Estimate Maintenance Task Duration
When creating a new maintenance schedule, one of the more challenging yet essential tasks is determining how long a specific task should take to complete.
Why is that the case?
Because your estimate for the duration of maintenance tasks can make the difference between smooth running operations and those disrupted by costly downtime.
Now, trying to determine how long each task should take, but having data makes this task possible.
It’s almost like reading the third book in a trilogy without reading the first two parts.
You’ll have no idea what is going on and probably make all the wrong conclusions due to a lack of context.
That is why Daniel McGowan, Offshore Projects Director at Longitude Engineering, highlights the importance of making data-based assumptions when planning and scheduling maintenance.
Illustration: WorkTrek / Quote: Add Energy
This brings us to the key question: how exactly do you do that?
Start by reviewing the data from previously completed maintenance jobs and use it to identify patterns and anomalies.
How long did the same or similar tasks take to complete?
Are the workers who completed them truly the most efficient, or do you have other technicians who could complete them faster next time around?
Did your technicians encounter any unexpected obstacles that prolonged the task duration?
Asking questions like these will help you create better time estimates going forward, and your CMMS can be a great source of answers.
In the example below, you can see the task being finished sooner than expected, giving you an idea of how much time you should reserve for it next time.
Source: WorkTrek
On top of that, it is wise to observe some key KPIs, such as your MTTR, or mean time to repair.
This important KPI measures the average time needed to complete a repair, providing you with a baseline for future upkeep scheduling.
You can calculate it using the following formula:
MTTR = Total Repair Time ÷ Total Number of Repairs.
Alternatively, you can use our handy maintenance calculator to quickly calculate both your MTTR and a variety of other key maintenance metrics.
Of course, the goal is to keep your MTTR as low as possible, as this indicates that both your scheduling and maintenance practices are effective.
Source: WorkTrek
The bottom line is that one of the best ways to estimate the duration of future maintenance activities is to look at the past.
Do your best to identify patterns and pay attention to cold, hard data, and you’ll excel at making this important estimation.
Conclusion
While scheduling maintenance tasks is no easy feat, we believe that following the tips we shared throughout this article can certainly make it more manageable.
With the right blend of technology, historical and real-time data, and collaboration with key stakeholders at your facility, you can make sure that everything keeps running smoothly—both your machinery and your operations.
And if you’re still worried about how you’re going to juggle everything that goes into good maintenance scheduling, we suggest you start with tip #1: make the most of your CMMS.
Just that one piece of technology can make a world of difference and help you implement the rest of the advice we shared.

Compliance & Control
Ultimate Guide to writing a Standard Operating Procedure
Standard Operating Procedures (SOPs) are key tools for businesses. They help teams work better and make fewer mistakes. A good SOP breaks down tasks into simple steps that anyone can follow.
Writing an SOP might seem difficult, but it's not. The key is to be clear and thorough. This article will guide you through the steps to write a SOP.
Start by picking the right format. There are several SOP formats, such as simple steps or flowcharts.
Source: WorkTrek
Next, gather all the needed info. Talk to the people who do the job every day. They know the task best. Then, write out each step in order. Use plain language that's easy to understand.
Add pictures or diagrams if they help explain things better. Remember to test the SOP to ensure it works well in real life.
[ez-toc]
Listen to this Article
Planning Your SOP
Good SOP planning involves three key steps. These steps help create a clear, useful document for everyone involved.
Identifying Stakeholders
Stakeholders play a big role in SOP creation. They include staff using the SOP and managers overseeing the process.
Illustration: WorkTrek / Quote: Linkedin
To find stakeholders:
List all departments affected by the SOP
Note key people in each department
Include customers if the SOP impacts them
Talk to these stakeholders. Get their input on the current process and ask about their problems. This will help create a better SOP.
Defining Scope and Objectives
The scope sets the SOP's limits. It says what the SOP covers and what it doesn't. A clear scope prevents the SOP from getting too big.
Objectives are the goals of the SOP. They explain why it's needed. Good objectives are:
Specific
Measurable
Achievable
Illustration: WorkTrek / Data: Collato
Write down the scope and objectives. Share them with stakeholders.
Make sure everyone agrees before moving on.
Determining the Format and Content
The SOP format depends on the process's complexity. Simple tasks need simple formats, while complex tasks need more detail.
Common SOP formats include:
Step-by-step lists
Flowcharts
Checklists
For content, think about the SOP's audience. New hires need more detail. Experts need less. Include these parts:
Purpose
Needed materials
Safety info
Step-by-step instructions
Troubleshooting tips
Use clear, simple language. Add visuals like diagrams if they help explain the steps.
SOP Structure
A well-organized Standard Operating Procedure (SOP) helps readers quickly find and understand important information. The structure typically includes a title page, a table of contents, and clearly defined sections with hierarchical steps.
Title Page and Table of Contents
The title page is the first thing readers see. It should include the SOP name, document number, and revision date. The company logo and department name are also often included.
Source: WorkTrek
The table of contents lists all major sections and subsections with page numbers, helping readers navigate the document easily.
Source: WorkTrek
A good table of contents is detailed but not overly long. It should cover the main topics and essential subtopics.
Sections and Hierarchical Steps
SOPs are divided into logical sections. Each section focuses on a specific part of the process.
Steps within sections use a hierarchical format:
Main step 1.1 Sub-step 1.2 Sub-step
Next main step 2.1 Sub-step 2.2 Sub-step
This format makes complex procedures easier to follow. It breaks tasks into manageable chunks.
Use clear, action-oriented language for each step. Start with verbs like "Click," "Enter," or "Select."
Roles and Responsibilities
This section outlines who does what in the procedure. It clarifies team member duties within the process.
Illustration: WorkTrek / Quote: Peter Simoons
A table can effectively show roles and tasks:
Role Responsibilities Manager Approve final document Technician Perform steps 1-5 Quality Control Check output in step 6
Include any special qualifications or training needed for each role. This ensures the right people handle each task.
Writing the SOP
Creating a clear and effective Standard Operating Procedure requires careful planning and attention to detail. The following steps will guide you through writing an SOP that is easy to understand and follow.
Creating Clear, Step-by-Step Procedures
Source: WorkTrek
When writing an SOP, it's crucial to break down complex tasks into simple, manageable steps. Start by listing all the actions needed to complete the process. Then, arrange these steps in a logical order.
Use numbered lists for sequential tasks. Use bullet points for tasks that can be done in any order. Each step should be concise and action-oriented.
Include any necessary safety guidelines or precautions at the beginning of the procedure. This ensures that workers are aware of potential hazards before starting the task.
It's also helpful to note the expected outcome of each step. This allows workers to check their progress and ensure they're on the right track.
Incorporating Visuals: Flowcharts and Diagrams
Visual aids like flowcharts and diagrams can significantly enhance the clarity of an SOP. They provide a quick overview of the process and help workers understand the relationship between different steps.
Flowcharts are handy for processes with decision points. They show the different paths a procedure can take based on specific conditions.
Source: WorkTrek
Diagrams can illustrate equipment setups, parts of a machine, or the layout of a workspace. These visuals can help prevent confusion and reduce errors.
When creating visuals, keep them simple and easy to read. Use clear labels and consistent symbols. Color coding can be helpful, but ensure the SOP is still understandable in black and white.
Using Clear and Simple Language
The language used in an SOP should be straightforward to understand. Avoid technical jargon unless it's necessary for the job. If industry-specific terms must be used, provide clear definitions.
Write in short, direct sentences. Use active voice to make instructions clear. For example, write "Turn off the machine" instead of "The machine should be turned off."
When writing, consider the audience's language abilities. If the SOP will be used by non-native English speakers, use simple vocabulary and avoid idioms or colloquialisms.
Be consistent with terminology throughout the document. If a piece of equipment is called a "conveyor belt" in one section, don't refer to it as a "transport system" in another.
Ensuring Compliance and Quality
Standard Operating Procedures play a key role in maintaining compliance and quality standards. They help organizations meet regulatory requirements, implement quality control measures, and ensure workplace safety.
Meeting Regulatory Standards
SOPs are essential for meeting regulatory standards in various industries. They outline specific steps to comply with regulations from agencies like the EPA and DOT.Organizations should:
Research relevant regulations for their industry
Include compliance steps in SOPs
Update SOPs when regulations change
Train employees on compliance procedures
SOPs help track and document compliance activities. This is crucial for audits and inspections. Companies can use SOPs to show they follow required practices and standards.
Quality Control and Assurance
Quality control and assurance are vital for consistent products and services. SOPs support these efforts by:
Defining quality standards
Outlining inspection processes
Specifying testing procedures
Establishing documentation practices
SOPs help maintain ISO 9001 certification. They provide a framework for continuous improvement, and when included in SOPs, quality checks become routine.
Employees can refer to SOPs for correct quality procedures. This reduces errors and improves product consistency. SOPs also help identify and address quality issues quickly.
Health and Safety Warnings
SOPs are crucial for workplace safety. They should include clear health and safety warnings. This helps prevent accidents and protects employees.
Illustration: WorkTrek
Key elements to include:
Hazard identification
Required safety equipment
Emergency procedures
First aid instructions
SOPs should highlight potential risks in each step. They can specify how to handle dangerous materials safely. Clear safety instructions reduce workplace injuries.
Regular safety training based on SOPs is important. This ensures all employees understand and follow safety protocols. SOPs should be updated when new safety risks are identified.
Testing and Validation
Testing and validation are key steps to ensure a Standard Operating Procedure (SOP) works well. These steps help find and fix any issues before the SOP is used.
Conducting Internal Reviews
Internal reviews check whether the SOP meets all rules and standards. A team of experts examines each part of the SOP to ensure it is clear, correct, and follows company policies.
The review team uses a checklist to test the SOP. They check things like
Is the language easy to understand?
Are the steps in the correct order?
Does it cover safety rules?
They also trial-run the SOP. This helps them identify any steps that are difficult to follow or don't work well.
Gathering Feedback from End-Users
End-users are the people who will use the SOP every day. Their input is very important. Here's how to get their feedback:
Give them the draft SOP to try out.
Ask them to note any confusing parts.
Have them fill out a survey about the SOP.
Watch them use the SOP and see where they struggle.
Illustration: WorkTrek / Quote: Muuk Test
This feedback helps make the SOP more user-friendly. It also finds problems that experts might miss.
Making Necessary Revisions
After reviews and feedback, it's time to make changes. This step is crucial for quality control.
The SOP writer looks at all the comments and suggestions. They decide which changes to make. Some standard revisions are:
Adding missing steps
Making instructions clearer
Fixing errors in the process
After changes are made, the SOP goes through testing again. This cycle may repeat until the SOP works well for everyone.
Implementing the SOP
Implementing a Standard Operating Procedure requires careful planning and execution. Effective implementation ensures that the SOP becomes an integral part of organizational operations.
Training and Communication
Training employees is crucial for successful SOP implementation. Develop a comprehensive training program that covers all aspects of the procedure.
Use a variety of training methods:
Classroom sessions
Hands-on practice
E-learning modules
Communicate the SOP's importance to all staff members. Explain how it contributes to organizational goals and improves efficiency.
Create a feedback loop to address questions and concerns. This will help refine the SOP and ensure everyone understands their role.
Regular refresher courses keep employees up-to-date with any changes or updates to the procedure.
Ensuring Accessibility and Understanding
Source: WorkTrek
Make the SOP easily accessible to all relevant personnel. Store it in a central location, such as a shared drive or intranet portal.
Create different versions of the SOP to cater to various learning styles:
Text-based documents
Flowcharts
Video tutorials
Use clear, simple language to enhance comprehension. Avoid jargon and technical terms unless necessary.
Provide a glossary for any specialized terms used in the SOP. This helps ensure consistent understanding across the organization.
Encourage employees to ask questions if anything is unclear. Foster an environment where seeking clarification is welcomed and encouraged.
Monitoring and Management
Review the SOP regularly to ensure it remains current and effective. Set up a schedule for periodic evaluations, such as quarterly or annually.
Monitor adherence to the SOP through:
Direct observation
Performance metrics
Quality control checks
Collect feedback from employees who use the SOP daily. Their insights can reveal areas for improvement or potential issues.
Track key performance indicators (KPIs) related to the SOP. This helps measure its impact on organizational efficiency and productivity.
Be prepared to make adjustments based on monitoring results. An SOP should be a living document that evolves with the organization's needs.
Designate a person or team responsible for managing and updating the SOP. This ensures consistent oversight and timely revisions when needed.
Reviewing and Maintaining SOPs
Standard operating procedures need continuous improvement to remain useful. Regular reviews, timely updates, and proper storage keep SOPs accurate and accessible.
Scheduling Regular Reviews
Source: WorkTrek
Set up a review schedule for SOPs. Decide how often each procedure needs to be checked. This could be yearly, quarterly, or monthly.
Assign reviewers who know the processes well. They should look for outdated steps, new rules, or better ways of doing things.
Use a checklist to guide the review:
Are all steps still correct?
Do safety measures need updates?
Have any laws or rules changed?
Can anything be made clearer?
Keep a log of when reviews happen and what changes were made. This helps track the SOP's history.
Updating SOPs in Real-Time
Don't wait for scheduled reviews to fix SOPs. Update them as soon as changes happen.
Set up a system for workers to suggest improvements. This could be a form or a regular meeting.
When updating:
Mark the new version clearly
Note what changed and why
Get approval from the right people
Tell everyone about updates right away. Use emails, meetings, or training sessions to spread the word.
Document Control and Storage
Use a clear naming system for SOPs. Include the date and version number in file names.
Store SOPs where everyone can find them easily. This might be a shared drive or a special software.
Source: WorkTrek
Control who can change SOPs. Only let authorized people make edits.
Keep old versions for records, but ensure everyone uses the latest one.
Back up SOPs regularly to prevent loss. Consider both digital and physical copies for important procedures.
Use clear file organization to group related SOPs together. This makes it easier to find and update connected procedures.

Compliance & Control
What Is Responsibility Assignment Matrix (RACI)?
Maintenance organizations often experience confusion and delays due to unclear roles and responsibilities, leading to inefficiencies and increased downtime.
Without clear accountability, tasks may be neglected, decision-making can become muddled, and communication breakdowns slow progress.
A Responsibility Assignment Matrix (RACI) addresses these issues by defining who is Responsible, Accountable, Consulted, and Informed for each task. This clear structure streamlines processes enhances communication and ensures that maintenance tasks are completed on time, reducing downtime and improving overall operational efficiency.
Source: Triaster
[ez-toc]
What is a Responsibility Matrix?
In project management, a RACI is essential for delineating the roles and duties attached to diverse tasks.
This matrix is commonly known as a RACI chart and distinguishes between four key role types:
Responsible
Accountable
Consulted
Informed
Source: WorkTrek
The core aim of devising a RAM is to ensure that every task is executed efficiently while averting any overlap or oversight in responsibilities.
A responsibility matrix bolsters team supervision by outlining specific roles, duties, and degrees of authority. It helps all individuals grasp their distinct contributions to the undertaking, thus promoting better project outcomes.
Allocating each task singularly to one person is crucial to maintaining explicitness within this structure. Incorporating all pertinent stakeholders into this framework comprehensively ensures that neglectful exclusions are prevented.
This mechanism defines team members’ functions and demonstrates their relationship to the larger objectives within the venture.
Key Components of a Responsibility Matrix
A RACI matrix is a responsibility assignment framework that delineates duties and obligations for different activities, project stages, or pivotal decisions. It is an acronym where “RACI” stands for Responsible, Accountable, Consulted, and Informed.
Each term designates a specific role within the team that helps restrict the responsibilities associated with each task.
Illustration: WorkTrek / Quote: Forbes
This systematic technique guarantees that every team member is aware of their respective individual tasks and the level of engagement required during the project's implementation phase.
This tool maps out how tasks are shared among project team members. This aids in clarifying roles to ensure clarity on who takes ownership (responsible), holds oversight (accountable), gives input (consulted), and needs updates (informed) regarding every assigned task.
Such precise attribution defines each participant’s degree of involvement and promotes seamless cooperation toward effective execution.
When dissecting each designated role further, each bears its unique significance and function. It’s critical to comprehend what being responsible, accountable, consulted or informed entails within this context.
Responsible
In a RACI matrix, the ‘Responsible’ role denotes the team member or members performing the actual work. This individual is typically profoundly involved in executing tasks and directly contributes to their successful completion. For each essential task within a project, it’s crucial to have an assigned responsible party to guarantee that the work meets project standards and reaches completion.
Illustration: WorkTrek / Data: Ninety
Clarifying who is responsible for specific project tasks removes uncertainty and reinforces accountability. The responsible person position usually falls on those team members actively carrying out duties pertinent to fulfilling project objectives.
Selecting appropriate individuals for this pivotal role is key to sustaining quality and progress throughout a project.
Accountable
Within the RACI matrix, define a distinct ‘Accountable’ role.
The person in this position is charged with achieving project goals and possesses the final decision-making power. To avoid ambiguity and sustain clarity in decisions, each task must be allocated to only one accountable individual.
Illustration: WorkTrek / Data: Workboard
Ensuring that there’s just a single accountable party for every task provides an unambiguous chain of command and authority. This appointed person is responsible for whether the task meets its intended outcome and must assign specific duties to others to complete it correctly.
Their function is vital in overseeing progress and certifying that tasks align precisely with set objectives.
Consulted
In a RACI matrix, the ‘Consulted’ designation is assigned to those individuals or groups that offer their advice and perspectives as a task is being carried out.
These consulted parties ensure that all relevant viewpoints have been acknowledged and considered. For instance, within the context of a project, one might seek a technical architect's specialized knowledge on technology-related matters.
Members of the team who fall under the ‘Consulted’ category need to be prepared for inquiries so they can contribute accordingly to the accountable parties and project stakeholders.
They provide insights for well-informed decisions and improve the quality of work involved in any given task. This practice of effective consultation ensures tasks align with larger project objectives and meet stakeholder expectations.
Informed
Project managers are important in ensuring that informed team members, including suppliers and stakeholders, are consistently updated with the project’s advancements. These consulted and informed parties need to know where things stand and how they might affect their interests.
These individuals are central to the project as they need insights into its progress without being active participants in task execution.
You will promote improved communication and maintain alignment throughout the project's duration by delivering regular updates to these team members.
Benefits of Using a Responsibility Matrix
Utilizing a RACI matrix within a project can markedly improve communication and maintain stakeholder awareness by precisely outlining roles.
This simple yet effective instrument aids in upholding project standards and streamlining role distribution, thereby averting responsibility duplication while ensuring each task has an assigned proprietor.
In larger teams, assigning responsibilities can reduce role ambiguity and pinpoint task responsibilities.
Illustration: WorkTrek / Data: Ninety
Implementing the RACI model promotes accountability among team members by fostering clear comprehension of individual obligations, reducing uncertainty regarding who owns which task.
Such clarity not only plays a crucial role in ensuring that no tasks fall through the cracks but also assists in keeping projects on track and identifying areas where efficiency could be improved.
Steps to Create a Responsibility Matrix
Developing a responsibility assignment matrix (RAM) starts with gaining an in-depth knowledge of the project. Initiating a RAM without grasping the complete scope and nuances of the project can cause misunderstandings and result in poorly assigned roles.
All project team members must be involved from the outset so they have clear insight into their specific tasks and responsibilities.
The methodology involves four primary steps: outlining all tasks associated with the project, determining who is on your team, attributing RACI roles to each task for each member, and thoroughly reviewing and communicating this vital matrix.
Each phase plays an essential role in crafting a meticulous RAM that effectively directs every aspect concerning responsibilities within the team for various tasks throughout your undertaking.
Define Project Tasks
The initial phase of developing a RACI chart is delineating the project tasks. This enumeration must encompass all duties, deliverables, milestones, and major decisions pivotal to the project's success. Such organized cataloging guarantees that each aspect of the project is addressed and prevents any essential assignments from being missed.
Illustration: WorkTrek / Data: Atlassian
Providing an explicit task inventory offers guidance and focus for the project team. It aids in monitoring advancement and ascertains that every necessary specific activity is recognized and allocated correctly, thereby aiding in achieving collective success in the venture.
Identify Team Members
The subsequent phase requires pinpointing every individual associated with the project, encompassing team members and stakeholders. This action guarantees that all participants are recognized and their specific duties within the project are distinctly established.
Identifying the appropriate individuals is essential for fostering efficient communication. This ensures that there is only one way of communicating during project execution.
Assign RACI Roles
After enumerating the tasks and recognizing the team members, allocating RACI roles for every task is essential. This process requires establishing who will be in charge, held accountable, consulted with, and kept informed regarding each action and output.
Illustration: WorkTrek / Data: Niagara Institute
Establishing well-defined RACI roles is instrumental in monitoring responsibilities and guarantees that all individuals know their precise obligations. Such a measure is vital to preserve clarity within the project framework and avert any duplication or misunderstanding concerning the distribution of tasks.
Review and Communicate
The last step involves reviewing the responsibility matrix with the team to confirm that all roles are well-defined and understood. We can finalize the RACI matrix through effective communication and feedback sessions, guaranteeing its correct and thorough completion while keeping the team on the same page.
This process is crucial for clearly defining each person’s roles and responsibilities within the project, ensuring everyone is aware of what they need to contribute.
Practical Examples of Responsibility Matrices
A responsibility matrix is a graphic instrument that delineates the roles and duties of different stakeholders within a project.
For example, when charting a business process, the business analyst may be responsible for actively completing the task at hand.
Likewise, when embarking on new product development or ventures aimed at growth, the consulted parties are essential contributors due to their specialized knowledge and critique.
Such instances underscore how effectively utilizing a Responsibility Assignment Matrix (RAM) across varying contexts can facilitate transparency and streamline processes within projects.
Best Practices for Implementing a Responsibility Matrix
Consistently revising and refreshing the responsibility matrix at various stages in the project lifecycle ensures that information remains current, thus eliminating any ambiguity surrounding role assignments.
Task delegation is streamlined by limiting the number of ‘Responsible’ roles assigned, and accountability stays distinct.
Following established guidelines helps to maintain the RACI as an effective instrument for overseeing responsibilities within a project, thereby improving both its efficiency and eventual outcome.
Common Pitfalls to Avoid
A frequent misstep with using a RACI matrix is assigning the ‘Responsible’ role for a single task to numerous stakeholders. This can cause disarray and reduce productivity.
An overly extensive project team may make the responsibility matrix more complex and challenging to manage and execute.
To implement the RACI matrix effectively, ensure that conflicts are resolved promptly and uncertainties about roles are dispelled. Lack of clear communication regarding roles and responsibilities might result in misunderstandings and a lack of cohesion within the project team.
Summary
The Responsibility Assignment Matrix (RAM) is an essential tool in project management. It ensures that roles and responsibilities are clearly defined and communicated.
Using a RACI matrix, project managers can enhance communication, maintain project expectations, and prevent overlaps in responsibility. Embrace the power of a Responsibility Assignment Matrix to bring clarity and order to your project management processes.

Operations & Maintenance
How to write a SOP for Maintenance Organizations
Many organizations struggle with inconsistent maintenance practices, leading to increased downtime, safety hazards, and costly repairs. Without a standardized approach, teams often miss critical steps or perform tasks incorrectly, affecting productivity.
This inefficiency can lead to operational delays, unexpected equipment failures, and higher costs, ultimately hindering business growth and performance.
Illustration: WorkTrek / Quote: Know Industrial Engineering
Implementing Standard Operating Procedures (SOP) for maintenance ensures consistency, clarity, and compliance across the board. Organizations can reduce errors, optimize resource allocation, and enhance overall efficiency by standardizing tasks, improving performance, and achieving cost savings over time.
[ez-toc]
Listen to this Article
What is Maintenance SOP?
Maintenance SOPs provide a structured approach to equipment care and facility upkeep. They ensure safety, efficiency, and consistency across maintenance tasks.
Definition of SOP
A maintenance SOP is a detailed guide that outlines specific steps for carrying out maintenance tasks. It sets clear standards for work quality and safety practices.
These documents are crucial for several reasons:
They promote consistency in maintenance work
SOPs reduce errors and improve safety
They help train new staff quickly and effectively
SOPs increase efficiency by standardizing processes
Source: WorkTrek
Maintenance SOPs also ensure compliance with regulations and industry standards. They create a system of accountability and help track maintenance history.
Core Components
Effective maintenance SOPs include several key elements:
Scope and objectives
Safety precautions
Required tools and equipment
Step-by-step procedures
Quality control checks
A good SOP starts with clear goals and a defined scope. It lists all necessary safety gear and precautions. The procedure section breaks down tasks into simple, easy-to-follow steps.
Source: WorkTrek
Quality control measures ensure the work meets standards. SOPs often include checklists or sign-off procedures. They may also specify how to document completed work.
Regular reviews and updates keep SOPs relevant and effective, ensuring they reflect current best practices and equipment changes.
Developing Effective Maintenance SOPs
Creating useful maintenance SOPs involves getting input from workers, making clear documents, and improving them over time. Good SOPs help maintenance teams work better and keep equipment running smoothly.
Gathering Input From Stakeholders
Stakeholders play a key role in making SOPs. Talk to maintenance techs, supervisors, and operators. They know the jobs best.
Ask about common tasks, safety concerns, and equipment needs. Make a list of all maintenance activities.
Hold meetings to discuss procedures. Take notes on important steps and tips.
Look at past repair records to find problem areas. Check if any rules or laws apply to the work.
Get photos or videos of tasks being done right. These can go in the SOP later. Having input from many people helps make SOPs that work well in real life.
Creating SOP Documents
Write SOPs in simple, clear language. Use short sentences and bullet points. Start with the task's goal. List needed tools and safety gear.
Break jobs into step-by-step instructions. Number each step. Use photos or diagrams to show key parts. Make a checklist for workers to follow.
Source: WorkTrek
Include these parts in each SOP:
Task name and ID number
Who does the task
How often to do it
Safety warnings
Step-by-step directions
What to do if something goes wrong
Use a standard format for all SOPs. This makes them easy to read and update.
Incorporating Feedback and Revisions
Test new SOPs before using them fully. Have workers try following the steps. Watch for any confusion or missed items. Ask for their thoughts on how to improve the SOP.
Provide a way for staff to give feedback anytime. Put a note box in the work area, or use a CMMS System to collect ideas. Review all suggestions regularly.
Update SOPs when equipment or methods change. Check quality standards to be sure SOPs still meet them. Revise steps that cause problems or delays.
Keep track of all SOP changes. Use version numbers. Tell workers about updates. Train them on new steps. Good SOPs grow and improve over time.
Implementation Strategies
https://www.youtube.com/watch?v=JG8hcdzvpMM
Implementing maintenance SOPs requires a well-planned approach. This involves clear communication, defined roles, and proper resource allocation.
Communication and Training
Strong communication is essential for the effective implementation of maintenance SOPs. Teams must understand the new procedures and their importance.
Training sessions should be held to explain the SOPs in detail. These can include hands-on practice and Q&A periods.
Illustration: WorkTrek / Data: Whale
Regular updates keep staff informed of any changes. This helps ensure everyone follows the latest procedures.
Feedback channels allow workers to voice concerns or suggest improvements. This creates a culture of continuous improvement.
Assigning Roles and Responsibilities
Clear role assignments are crucial for SOP success. Each team member should know their specific duties.
A responsibility matrix that lists tasks and the people accountable can help clarify who does what.
Supervisors should oversee SOP compliance. They can offer guidance and address any issues that arise.
Regular performance reviews can track how well staff follow SOPs. This helps identify areas for improvement or additional training.
Tools and Resources Allocation
Proper tools and resources are essential for effective SOP implementation. This includes both physical equipment and digital systems.
Maintenance management software can help track work orders and SOP compliance. It provides a central platform for accessing procedures.
Safety gear and specialized tools should be readily available. This ensures workers can follow SOPs without delay.
Budget allocation for ongoing training and equipment upgrades is important. This keeps the maintenance team up-to-date with best practices and technology.
Safety and Compliance
Safety and compliance are key parts of maintenance SOPs. They protect workers and keep things legal. Rules, safety steps, and industry standards all play a role.
Understanding Regulatory Requirements
Regulatory requirements set the rules for maintenance work, and companies must know and follow them. OSHA standards often apply to maintenance tasks.
Source: WorkTrek
Some common rules include:
Proper machine guarding
Lockout/tagout procedures
Electrical safety standards
Breaking these rules can result in fines or legal trouble. Therefore, it's crucial to stay current on changing regulations.
Incorporating Safety Protocols
Safety protocols are steps to prevent harm. They should be a core part of every maintenance SOP.
Key safety measures include:
Using the correct personal protective equipment (PPE)
Following proper tool-handling procedures
Identifying and marking hazards
Regular safety training helps workers remember these protocols. Review and update safety steps often.
Ensuring Compliance with Industry Standards
Industry standards go beyond basic rules. They set best practices for maintenance work, and following these standards can improve safety and quality.
Common industry standards include:
ISO 9001 for quality management
ISO 14001 for environmental management
ISO 45001 for occupational health and safety
Maintenance SOPs should align with these standards. This helps ensure work is done safely and correctly, making it easier to pass audits and inspections.
Regular reviews can help keep SOPs in line with changing standards. It's important to document how the SOP meets each standard.
Maintenance Execution
Effective maintenance execution involves regular inspections, timely repairs, and proper documentation. These practices help keep equipment running smoothly and prevent unexpected breakdowns.
Conducting Inspections and Preventive Maintenance
Regular inspections are crucial for identifying potential issues before they become major problems. Maintenance teams should create checklists for each piece of equipment, noting key components to examine.
Source: WorkTrek
Preventive maintenance tasks may include:
Lubricating moving parts
Tightening loose bolts
Cleaning filters
Checking fluid levels
These tasks should be scheduled based on manufacturer recommendations and equipment usage patterns. It's important to train staff on proper inspection techniques and safety procedures.
Maintenance teams should use digital tools to track inspection results and schedule follow-up actions. This helps ensure no issues are overlooked and allows for trend analysis over time.
Equipment Repair and Parts Management
When repairs are needed, technicians should follow standardized procedures to diagnose and fix issues. This may involve:
Troubleshooting steps
Repair instructions
Safety precautions
Potential safety hazards
Source: WorkTrek
A well-organized parts inventory is essential for quick repairs. Maintenance departments should:
Keep commonly used parts in stock
Track part usage and reorder points
Store parts properly to prevent damage
A computerized maintenance management system (CMMS) can help streamline parts ordering and tracking, reducing equipment downtime and improving repair efficiency.
Recording and Reporting Procedures
Accurate maintenance records are needed to track equipment history and identify recurring issues. Technicians should document:
Date and time of maintenance activities
Work performed and parts used
Equipment condition before and after maintenance
Any unusual findings or concerns
Source: WorkTrek
Regular reporting helps management make informed decisions about equipment replacement and maintenance strategies. Monthly or quarterly reports should include:
Equipment uptime and downtime statistics
Cost of repairs and parts
Trends in maintenance needs
Using digital tools for recording and reporting can improve data accuracy and make it easier to analyze maintenance performance over time.
Performance Evaluation and Improvement
Evaluating and improving maintenance performance is crucial for keeping operations running smoothly. Tracking key metrics, analyzing downtime, and implementing continuous improvement help boost efficiency and reliability.
Tracking Maintenance Metrics
Maintenance analytics in the form of Key Performance Indicators (KPIs) are essential for measuring and optimizing maintenance performance. Standard metrics include equipment uptime, mean time between failures, and maintenance costs.
Managers should track both leading and lagging indicators. Leading indicators predict future performance while lagging indicators show past results.
Key metrics to monitor:
Equipment availability
Planned vs unplanned maintenance
Work order completion rate
Spare parts inventory turnover
Regular review of these metrics helps identify trends and areas for improvement. Teams can use dashboards or reports to visualize data and spot issues quickly.
Analyzing and Addressing Downtime
Downtime analysis is critical for improving maintenance efficiency. Teams should track both planned and unplanned downtime and categorize reasons for equipment failures.
Steps to address downtime:w
Collect detailed data on each incident
Identify root causes using techniques like 5 Why analysis
Develop action plans to prevent recurring issues
Implement predictive maintenance where possible
Illustration: WorkTrek / Data: Trilio
Prioritize efforts on equipment that will have the highest impact on productivity. Cross-functional teams can collaborate to find innovative solutions to chronic problems.
Regular downtime review meetings help keep everyone focused on improvement goals. Teams should celebrate successes and learn from setbacks.
Continuous Improvement Process
Continuous improvement is vital for long-term maintenance success. It involves regularly reviewing and updating processes to adapt to changing needs and technologies.
Key elements of a continuous improvement process:
Regular performance reviews
Employee feedback and suggestions
Benchmarking against industry best practices
Training and skill development programs
Teams should set clear improvement goals and track progress over time. Small, incremental changes often lead to significant gains in efficiency and quality.
Illustration: WorkTrek / Quote: Manutan
Encourage a culture of innovation where staff feel empowered to suggest ideas. Pilot new approaches on a small scale before fully implementing them.
Technology can support improvement efforts through better data collection and analysis. Consider investing in maintenance management software to streamline processes.
Maintenance Optimization
Maintenance optimization improves efficiency, reduces costs, and extends equipment life. It focuses on using technology, streamlining workflows, and enhancing reliability.
Leveraging Technology and CMMS
Computerized Maintenance Management Systems (CMMS) play a key role in maintenance optimization. These systems help track equipment, schedule tasks, and manage resources.
CMMS software stores equipment data, maintenance history, and spare parts inventory. This information helps managers make better decisions about maintenance needs.
Illustration: WorkTrek / Quote: Flowdit
With CMMS, teams can set up automatic alerts for scheduled maintenance. This ensures tasks are done on time, reducing the risk of breakdowns.
Mobile apps linked to CMMS allow technicians to access information and update records in real-time, improving accuracy and speeding up work completion.
Streamlining Maintenance Workflows
Efficient workflows are crucial for optimizing maintenance processes. Standard Operating Procedures (SOPs) provide clear guidelines for maintenance tasks.
SOPs outline step-by-step instructions for each maintenance job. This helps ensure consistency and quality in work performed.
Prioritizing tasks based on equipment criticality is important. Teams should focus on high-priority items first to minimize downtime.
Cross-training staff allows for more flexible scheduling and ensures that critical tasks can always be completed, even if specific team members are unavailable.
Regular team meetings help identify bottlenecks and areas for improvement. This ongoing feedback loop is essential for continuous optimization.
Extending Equipment Lifespan and Reliability
Planned Maintenance Optimization (PMO) strategies help extend equipment life and improve reliability. PMO involves analyzing maintenance data to create targeted maintenance plans.
Predictive maintenance techniques use sensors and data analysis to detect potential issues before they cause breakdowns. This approach can significantly reduce unexpected failures.
Regular inspections and preventive maintenance tasks keep equipment in good condition. Follow manufacturer recommendations for maintenance schedules.
Proper lubrication, cleaning, and equipment calibration are simple yet effective ways to extend its lifespan. Train staff on these basic maintenance tasks.
Tracking and analyzing equipment performance data helps identify patterns and potential problems. This information guides decisions about repairs or replacements.
Documentation and Manuals
Good documentation and manuals are key to effective maintenance. They provide clear instructions, help with training, and keep everyone on the same page.
Creating Visual Aids and Flowcharts
Visual aids and flowcharts make complex procedures easier to understand. They break down tasks into simple steps. Use clear diagrams to show equipment parts and how they fit together.
Flowcharts help organize decision-making processes and guide workers through troubleshooting steps. Create charts for common problems and their solutions.
Use colors and symbols to highlight important points. Keep designs simple and easy to read. Test visuals with staff to ensure they are helpful.
Updating Manuals as per Manufacturer Recommendations
Manuals need regular updates to stay useful. Check for new info from equipment makers often. This keeps procedures safe and up-to-date.
Illustration: WorkTrek / Data: Infotech
Set a schedule to review manuals. Look for changes in:
Safety guidelines
Operating instructions
Maintenance schedules
Maintenance processes
Emergency procedures
Part numbers
Add notes about common issues found on-site. This will make the manuals more helpful for your team. Share updates with all staff quickly.
Document Control and Record Keeping
Good record-keeping is vital for maintenance. It helps track work done and plan future tasks. Set up a system to organize all documents.
Use a central database for easy access. Include:
Equipment manuals
Repair histories
Inspection reports
Safety procedures
Control who can edit documents. This keeps info accurate. Use version numbers to track changes.
Keep backup copies of all records. This protects against data loss. Train staff on how to use and update the system properly.

Operations & Maintenance
6 Different Approaches To Equipment Maintenance Schedule
There is no denying that regular maintenance of your assets is important.
After all, it prevents breakdowns and keeps productivity high, contributing to the overall success of your facility.
But we’re here to argue that the way you approach the task of scheduling maintenance is what can truly make or break your operations.
In this article, we’re exploring six different approaches to this important process, comparing them, and sharing some actionable tips on how to make the most of each.
Let’s get right into it.
Time-Based Scheduling
One of the most straightforward approaches to maintenance is scheduling it at regular, predetermined time intervals, regardless of the asset’s condition or usage.
Time-based maintenance (TBM), also known as periodic maintenance, can seem appealing because it is predictable and easy to plan and schedule.
All you have to do is check manufacturer recommendations, put maintenance tasks into the schedule every X days, weeks, or months, and you’re done.
And even if the equipment is in good mechanical health and doesn’t need any maintenance, it’s better to be safe than sorry, right?
Well, not exactly.
Despite the convenient nature of TBM scheduling, this rigid approach isn’t always the best choice.
For starters, it can lead to over-maintenance of assets, which can cause more harm than good.
Charles Rogers, a Senior Software Implementation Consultant at Fiix, agrees.
Illustration: WorkTrek / Quote: Fiix
Performing maintenance on your assets for no reason other than “it says so in the schedule” can lead to a range of consequences, including:
increased maintenance costs,
unnecessary downtime,
faster asset depreciation, and
waste of your technicians’ time.
And you certainly don’t want any of that.
However, just as it can push you to conduct maintenance more often than necessary, time-based maintenance scheduling can result in maintenance activities that need to be more frequent.
For example, let’s say you schedule centrifugal pumps for inspection and maintenance every six months because they’re new, and you feel more frequent checks are unnecessary.
Since your technicians are sticking to this time-based schedule and looking at the pumps less frequently than recommended, missing the warning signs that something’s wrong with them becomes all too easy.
At this point, you might be thinking that TBM scheduling is no good and that you might be better off opting for a different approach altogether.
But Erik Hupjé, Founder and Managing Director of Reliability Academy, believes you can make it work.
This maintenance and reliability expert with over 20 years of experience says that time-based maintenance is best used for equipment whose failure is age-related.
Illustration: WorkTrek / Quote: LinkedIn
In other words, TBM is a solid choice for equipment whose failure patterns are predictable.
For instance, Hupjé explains, it’s only natural for equipment nearing the end of its useful life to experience a higher likelihood of failure.
Therefore, scheduling maintenance at regular intervals for such equipment might be just what you need.
But you don’t have to stop there.
TBM scheduling also works for equipment with predictable usage patterns.
Think about the equipment running for the same number of hours daily or at the same speed and frequency.
Such assets will experience more predictable wear and tear thanks to this consistency.
So if you opt for the time-based approach to maintenance scheduling for some of your equipment, don’t just blindly follow manufacturer recommendations or your discernment.
Make sure to combine both, and you’re bound to make the most of it.
Meter-Based Scheduling
If you feel like the time-based approach is too limiting and somewhat risky, a good alternative to consider is meter-based maintenance scheduling.
Rather than basing the frequency of maintenance tasks on strict time intervals, this approach requires you to track your equipment usage and schedule maintenance accordingly.
As such, it is more flexible than TBM but also more complex to set up and schedule.
Meter-based scheduling is based on defining usage metrics, such as the number of operating hours or cycle counts, and scheduling maintenance once that predefined usage threshold has been met.
Source: WorkTrek
However, just like time-based scheduling, this usage-based approach doesn’t consider the asset's condition at the time of scheduled maintenance.
So how is meter-based scheduling any different, then?
Well, it requires you to look at your own usage data to set and adjust a metric threshold that accurately reflects when maintenance is truly needed.
Simply put, while it doesn’t directly account for the asset's condition, meter-based scheduling lets you observe metrics that correlate with the asset's wear and tear.
Sticking with our centrifugal pump example, let’s say you’ve noticed that its bearings require lubrication about every 2,000 operating hours.
If the pump runs 24/7, it will take almost three months to reach that number of operating hours, but if you use it occasionally, it might take six months or more.
Time-based scheduling doesn’t account for this, so it would likely have you over-maintaining the pump and wasting resources.
Therefore, meter-based scheduling allows you to respond to the changing needs of your assets more accurately.
However, it also requires you to monitor the usage metrics of your assets actively.
And you’ll agree doing this manually can be pretty time-consuming and resource-intensive.
Luckily, with a maintenance management solution such as our WorkTrek, you can automate at least a part of this process.
Source: WorkTrek
All you need to do is enter your assets into the system and determine the thresholds at which maintenance should be initiated.
Setting this up in WorkTrek is incredibly easy—you simply need to fill out the required fields, as shown below.
Source: WorkTrek
Then, once the threshold you have set has been reached, you update this information in the system, and WorkTrek will automatically generate a work order, setting the maintenance process in motion.
Overall, if you’re working with equipment whose wear patterns can be determined based on meter readings, this type of scheduling could be a good approach for you to follow.
Condition-Based Scheduling
Another approach to maintenance scheduling that you might want to consider is condition-based maintenance scheduling, also known as CBM scheduling.
As its name suggests, this proactive approach is based on real-time monitoring of your equipment’s condition and performance.
We could say that CBM is an upgraded version of meter-based maintenance because it tracks health indicators in real time, triggering maintenance as soon as deterioration begins, regardless of usage or time.
This makes CBM a good choice if you’re looking to maximize your machines’ uptime and prevent unnecessary maintenance costs at your facility.
Yet, it’s a much less popular approach to maintenance scheduling than preventive and reactive maintenance, according to the MaintainX 2024 State of Industrial Maintenance Report.
Illustration: WorkTrek / Data: MaintainX
Why is this the case?
It could be that condition-based maintenance is less predictable than time- and meter-based options that follow a strict schedule.
On top of that, it is more complex to implement and manage, as it requires you to continuously collect real-time data using different types of analyses, such as:
Vibration Analysis
Analyzes the vibration patterns of equipment to detect issues like imbalances, misalignment, and bearing failures.
Infrared Analysis (Thermography)
Uses thermal imagers to identify abnormal heat patterns that can indicate electrical faults, misaligned components, or friction in mechanical systems.
Oil Analysis
Monitors the properties of oil fluid, like viscosity and acid levels, and detects the presence of contaminants, wear particles, and chemical degradation.
Ultrasonic Analysis
Detects high-frequency sounds and converts them into digital and audio data to identify issues that emit high-frequency noise, like leaks, electrical discharges, and mechanical anomalies.
Electrical Analysis
Measures the current in the circuit using clamp-on ammeters and detects whether a piece of equipment is receiving a normal amount of electricity.
Pressure Analysis
Monitors pressure levels to check for leaks, blockages, and structural integrity in pressurized systems.
As you can see, there are quite a few things to track if you want to properly monitor the mechanical health of your assets and schedule maintenance accordingly.
However, we’d say it’s worth the effort.
This certainly was the case for Končar, an industrial and electrical engineering company that decided to implement condition-based monitoring to protect its critical production motors.
They gained insight into all the critical parameters, from vibrations and speed of rotation to temperature levels.
Illustration: WorkTrek / Quote: Končar
This approach made it possible for them to schedule maintenance based on the actual condition of the equipment rather than on the assumption that wear and tear would occur after a specific amount of time or usage.
And the good news is that it can do the same for you, too.
Scheduling by Data-Based Predictions
The following method on our list relies on data-based prediction to schedule equipment maintenance.
In other words, predictive maintenance.
With data gradually becoming the backbone of successful plants and facilities, this maintenance management approach is gaining traction.
In fact, according to the MaintainX report we mentioned earlier, it’s the third most commonly used maintenance program, with 30% of facilities utilizing it.
Why?
Well, the Maintenance Supervisor at Cintas, a company that provides uniforms, facility services, and safety products, believes scheduling maintenance using data-based predictions helps facilities stay ahead of equipment issues.
Illustration: WorkTrek / Quote: MaintainX
In a way, predictive maintenance goes a step further than condition-based maintenance.
Aside from using condition-based diagnostics, the predictive maintenance approach relies on historical and real-time data and machine learning algorithms to predict potential failures.
So, while CBM tells you that maintenance is needed, predictive maintenance predicts when it may be needed.
Freddie Coertze, National IoT Business Manager for ifm Australia, explains why he advocates for predictive maintenance over CBM:
Condition monitoring with vibration analysis is simply not enough – by the time vibration has started, it’s often already too late to intervene and save the machine. To protect your assets, you need to predict.
But predictive maintenance doesn’t just protect your assets and prevent minor hiccups from turning into serious issues.
It also increases productivity and reduces breakdowns, maintenance planning time, and maintenance costs, reports Deloitte.
Illustration: WorkTrek / Data: Deloitte
These numbers show that predictive maintenance carries a lot of potential advantages for industrial facilities.
While its implementation can be more demanding due to the sheer amount of components it requires—from IoT devices and sensors to CMMS and data collection systems—the long-term benefits you can reap make predictive maintenance scheduling an approach worth considering.
Criticality-Based Scheduling
The criticality-based approach to maintenance scheduling prioritizes maintenance tasks in a way where the most critical equipment is taken care of first.
But how do you determine which equipment needs to receive maintenance first?
And how do you decide which assets’ failure poses a greater risk to your operations?
Well, that is where criticality analysis comes in.
Illustration: WorkTrek / Quote: UpKeep
This analysis will help you assess how significant each piece of equipment is for your organizational objectives and how big of an impact its failure would have on your operations.
To successfully conduct it, you first need to assemble a cross-functional team to help you develop an equipment criticality assessment matrix.
Its purpose is to help you visualize and rank your equipment’s criticality, making prioritizing its maintenance easier.
For starters, you want input from those within the organization affected by equipment failures—from maintenance engineers and operations managers to maintenance technicians.
From there, you’ll need to compile a list of all the equipment that needs to be assessed and then agree on criticality ranking criteria. These can include factors like the age and condition of the asset, its impact on the operations, the safety risks it carries, and the impact made by its downtime.
You then need to define how severe the consequence of failure is for each asset.
Lastly, you need to agree on how likely each piece of equipment will fail within a specified timeframe.
When you put all of these elements together, you’ll end up with a criticality assessment matrix such as the one you can see below.
Source: Click Maint
Using this systematic approach, you can confidently create a maintenance schedule that addresses the most urgent equipment inspections and fixes first.
This, in turn, keeps your operations running smoothly and helps you mitigate the safety risks of faulty equipment.
Scheduling Around Seasonality
The final approach we’re going to cover today focuses on scheduling maintenance activities around seasons.
The idea behind it is to schedule maintenance tasks in alignment with the seasonal variations in equipment use.
Why?
Because, by scheduling maintenance of specific assets during lower activity seasons, you can ensure that there are minimal to no disruptions to your operations during peak seasons.
Let’s take HVAC maintenance, for example.
Given that the usage of HVAC systems is increased during the summer and winter months, it comes as no surprise that many choose to schedule their maintenance during spring and fall.
Marcin Bizewski, Operations Director at Sescom Facility Management, explains why this is the case.
Illustration: WorkTrek / Quote: Sescom
Because scheduling around seasonality proactively addresses potential issues before they get the opportunity to happen, the risk of failures during peak usage season is decreased significantly.
Can you imagine working in 100°F heat just because you didn’t schedule a technician to look at the HVAC system in the springtime?
And we don’t even have to mention the fact that, if the unit breaks down, repairing or completely replacing it will cost you much more than a slot in the schedule for its maintenance would have.
So, don’t underestimate the power of scheduling maintenance of some of your assets based on seasonal changes.
For that, use your CMMS to plan and schedule them for a checkup ahead of time.
You can even create a checklist for seasonal maintenance tasks so that the technician performing them knows precisely which steps they need to follow, season after season.
Source: WorkTrek
Overall, scheduling particular maintenance activities based on seasonality is a great way to complement the other approaches to maintenance scheduling used at your facility.
Conclusion
And there you have it - six approaches you can choose from when deciding how and when you should schedule maintenance tasks for your equipment!
While having this many options might seem overwhelming at first glance, this variety can help you improve your maintenance planning and scheduling.
You don’t have to opt for just one of these approaches.
Instead, you can weigh the pros and cons of each and assess which equipment would benefit the most from each method.
Don’t forget to optimize the whole process using a CMMS, as this kind of solution will be your biggest ally in keeping your maintenance activities on track.

Operations & Maintenance
What is Mean Time to Acknowledge (MTTA)
Mean Time to Acknowledge (MTTA) is a key metric used in incident management. It measures how long a team will respond after an alert is sent out. MTTA is calculated by dividing the total time to acknowledge all incidents by the number of incidents over a set period. MTTA helps organizations track their response speed to issues. A low MTTA shows that a team is quick to act when problems arise. This can lead to faster problem-solving and less downtime for systems and services.
Source: WorkTrek
Tracking MTTA can point out areas where a team needs to improve. It can show if there are delays in noticing or responding to alerts. By working to lower MTTA, companies can boost their overall incident management process. This often results in better service for customers and fewer long-lasting issues.
Listen to a Podcast on MTTA
Understanding Mean Time to Acknowledge (MTTA)
https://www.youtube.com/watch?v=YBwSnc27tdM
Mean Time to Acknowledge (MTTA) is a key metric used in incident management. It measures the average time between an alert being issued and a team response.
MTTA helps track how quickly organizations react to incidents. A lower MTTA indicates faster response times, which are generally better for resolving issues promptly.
To calculate MTTA, teams add the total time to acknowledge all incidents. They then divide this by the number of incidents over a set period. For example:
10 incidents
40 minutes total acknowledgement time
MTTA = 40 minutes ÷ 10 incidents = 4 minutes
Source: WorkTrek
Incident management teams use MTTA to evaluate their performance. It helps identify areas for improvement in alert response processes. A good MTTA varies by industry and incident type. Some common ways to improve MTTA include:
Automating alert systems
Prioritizing critical alerts
Training staff on quick response procedures
Implementing clear escalation policies
By tracking and optimizing MTTA, organizations can enhance their incident management capabilities. This leads to faster problem resolution and improved service quality.
The Role of MTTA in Incident Management
MTTA helps teams respond faster to issues. It measures how quickly incidents are noticed and addressed.
Defining Incident Response
Incident response is how teams handle problems that pop up. It starts when an alert sounds, and the clock begins ticking as soon as the alert sounds.
MTTA measures the time from alert to when someone says, "I'm on it." A quick MTTA shows the team is on the ball, ready to jump into action when needed.
Illustration: WorkTrek / Quote: incident.io
Good incident response means:
• Watching for alerts
• Noticing problems fast
• Getting the right people involved
Teams use tools to track MTTA. These tools help them see how well they're doing.
The Importance of Quick Acknowledgement
Fast acknowledgment is key for solving problems quickly. When teams react fast, they can fix issues before they get worse.
Quick responses help in many ways:
• Keep customers happy
• Prevent big outages
• Save money
Reliability improves when MTTA is low. It shows that the team is always ready, and customers feel taken care of when problems are spotted quickly.
Illustration: WorkTrek / Quote: Splunk
Incident response teams use MTTA to get better. They look at their numbers and find ways to speed up. Sometimes this means:
• Better alert systems
• More staff on call
• Clearer response plans
A low MTTA helps teams prioritize. They know which issues need attention first.
Related Time-Based Metrics
Source: WorkTrek
Time-based metrics help measure system reliability and team performance. They provide insights into how quickly issues are resolved and how often they occur.
Mean Time to Failure (MTTF)
MTTF measures the average time a system operates before failing. It's used for non-repairable items that are replaced after failure.
MTTF is calculated by dividing the total operating time by the number of failures. A higher MTTF indicates better reliability.
For example, if a light bulb lasts 1000 hours before burning out, its MTTF is 1000 hours.
MTTF helps predict when components might fail. This allows for proactive maintenance and replacement.
Mean Time to Recovery (MTTR)
MTTR tracks the average time to fix an issue and restore service. It includes the entire process from detection to resolution.
MTTR is calculated by adding up all recovery times and dividing by the number of incidents.
A lower MTTR shows faster problem-solving and better incident management. It's a key metric for measuring team efficiency.
MTTR can be improved by:
Automating alert systems
Creating clear incident response plans
Providing staff with proper tools and training
Mean Time Between Failures (MTBF)
MTBF measures the average time between system failures. It's used for repairable items that can be fixed and returned to service.
Illustration: WorkTrek / Quote: intelliarts
MTBF is calculated by dividing total operating time by the number of failures over a set period.
A higher MTBF indicates better system reliability and stability. It helps predict how often maintenance might be needed.
MTBF can be improved by:
Regular system maintenance
Identifying and fixing recurring issues
Using high-quality components
MTBF is often used alongside MTTR to get a full picture of system performance.
Influencing Factors on MTTA Performance
Several key elements impact how quickly teams can acknowledge incidents. These factors shape an organization's ability to respond promptly and effectively to issues as they arise.
Incident Detection and Alerting
Effective incident detection plays a crucial role in MTTA performance. Reliable monitoring systems help teams spot problems early.
Alert quality is vital. Clear, actionable alerts help teams understand issues quickly, while noisy or vague alerts can slow response times.
Prioritization is key. Critical incidents should trigger immediate notifications. Less urgent issues can be handled later.
Proper alert routing ensures the right people are notified, preventing delays caused by alerts going to the wrong team members.
Communication and Collaboration
Strong communication channels speed up incident acknowledgment. Teams need easy ways to share information and updates.
Clear escalation procedures help route incidents to the right people. This prevents bottlenecks in the response process.
Illustration: WorkTrek / Data: firstup
Collaboration tools enable quick discussions and decision-making. Chat apps and video calls can bring teams together fast.
Regular training helps staff recognize and respond to alerts efficiently. This builds the skills needed for quick acknowledgment.
Automation and Tools
Automation tools and CMMS software can significantly reduce MTTA. They can handle routine tasks and speed up human responses.
Source: WorkTrek
Incident management platforms centralize information and streamline workflows. This helps teams work more efficiently.
Auto-acknowledgment systems can handle simple issues without human input. This frees up staff for more complex problems.
Integration between tools is crucial. When systems work together smoothly, teams can respond faster.
AI and machine learning can help predict and prevent incidents. This proactive approach can reduce the number of alerts teams face.
Improving MTTA in Your Organization
Reducing the Mean Time to Acknowledgement (MTTA) requires a multifaceted approach. Organizations can implement strategies to speed up incident response and boost efficiency.
Incident Prioritization Strategies
Prioritizing incidents is key to lowering MTTA. Set up a system to rank issues based on their impact and urgency. Use automation to flag critical problems.
Create clear guidelines for each priority level. This helps teams quickly assess and respond to alerts.
Consider these factors when prioritizing:
Number of affected users
Business impact
Potential data loss
Security risks
Regularly review and update your prioritization system. This ensures it stays relevant as your organization grows and changes.
Effective Alert Management
Good alert management is crucial for improving MTTA. Set up alerts that are clear, actionable, and relevant.
Use these tips to enhance your alert system:
Reduce alert noise by eliminating false positives
Group related alerts to avoid alert fatigue
Include context in alerts to help diagnose issues faster
Set up escalation policies for unanswered alerts
Implement a centralized alert management tool. This gives teams a single view of all incidents, making tracking and responding quickly easier.
Training and Knowledge Sharing
Invest in ongoing training for your incident response team. This builds their skills and confidence, leading to faster acknowledgment times.
Create a knowledge base with:
Common issues and their solutions
Troubleshooting guides
Escalation procedures
Illustration: WorkTrek / Data: Helpjuice
Encourage team members to share their experiences. Hold regular debriefs after major incidents to discuss what went well and areas for improvement.
Use simulations to practice handling different types of incidents. This helps teams stay prepared and respond more efficiently when real issues arise.
The Impact of MTTA on Key Organizational Outcomes
MTTA affects several crucial areas of business performance. It influences customer relationships, operational efficiency, and equipment maintenance practices.
Customer Satisfaction and Trust
Mean Time to Acknowledge (MTTA) directly impacts customers' perception of a company's service quality. Quick acknowledgment of issues shows customers their concerns are heard and valued.
Faster MTTA leads to higher customer satisfaction scores. Customers feel respected when their problems get swift attention. This builds trust and loyalty over time.
Illustration: WorkTrek / Quote: Forrester
Slow MTTA, on the other hand, can frustrate customers. They may feel ignored or unimportant. This can damage relationships and lead to customer churn.
Companies with low MTTA often see better reviews and more positive word-of-mouth. Customers appreciate responsive service and are more likely to recommend such businesses to others.
Operational Efficiency and Performance
MTTA is a key metric for evaluating incident management teams. It shows how quickly teams spot and respond to issues.
Lower MTTA often means faster problem resolution. When teams acknowledge issues quickly, they can start working on fixes sooner, leading to less downtime and better system reliability.
Efficient MTTA processes help maintain high uptime. Systems stay operational for longer periods, boosting overall performance.
Teams with good MTTA tend to be more proactive. They catch small issues before they become big problems, which saves time and resources in the long run.
Preventive Maintenance and Lifespan
MTTA plays a role in effective preventive maintenance strategies. Quick acknowledgment of minor issues helps prevent major breakdowns.
Low MTTA allows maintenance teams to address problems early, extending the lifespan of equipment and systems. Regular, timely maintenance based on quick issue detection keeps assets in good condition.
Illustration: WorkTrek / Data: FMX
Companies with efficient MTTA often see lower repair costs. By catching problems early, they avoid expensive emergency repairs or replacements.
Good MTTA practices contribute to better resource planning. Maintenance teams can schedule work more effectively when they know about issues promptly.
Developing an Effective MTTA Strategy
A strong MTTA strategy can boost incident response and cut downtime. It relies on clear procedures and smart technology use.
Establishing Clear Procedures and Expectations
Clear rules help teams respond faster to issues. Set up a system to rank incidents by their urgency.
This helps staff know which problems need attention first.
Illustration: WorkTrek / Quote: Business News Daily
Create a list of who to call for different types of incidents. Make sure everyone knows their role when an alert comes in. Train staff regularly on these procedures.
Set goals for how quickly alerts should be answered. These goals can be part of service level agreements (SLAs). Track if teams meet these goals and use the data to improve.
Good communication is key. Have a plan for how teams will talk to each other during an incident. This can include chat tools or phone trees.
Leveraging Technology and Innovation
The right tools can speed up alert response times. Use a system that sends alerts to the right people right away. Look for one that works on phones and computers.
Automate where you can. Set up rules to sort alerts by type and send them to the right team. This reduces human error and saves time.
Use data to get better. Track key performance indicators (KPIs) like MTTA and mean time to repair. Look at these numbers often to see where you can improve.
Consider AI tools that can predict issues before they happen. These can help teams be ready to act quickly when problems arise.
Test your systems regularly. Run drills to ensure everything works as it should. This will help you identify weak spots in your process.
Conclusion
Mean Time to Acknowledge (MTTA) is a key metric for maintenance organizations. It measures how quickly organizations respond to alerts and incidents.
MTTA tracks the average time between when an alert is created and when someone acknowledges it. A low MTTA indicates fast response times, while a high MTTA suggests delays.
Ultimately, a lower MTTA leads to faster incident resolution. This helps minimize downtime and reduce the impact of security threats or system issues.

Operations & Maintenance
What is MTTR
MTTR stands for Mean Time to Repair. It's a key metric that measures how quickly systems can be fixed after breaking down. MTTR helps companies understand and improve their reliability and availability. When equipment fails, it costs time and money. A low MTTR shows that repairs happen fast, which means less downtime and happier customers.
Source: WorkTrek
Companies track MTTR to spot problems and improve their repair processes. MTTR helps identify areas for improvement in repair procedures. It can reveal if teams need more training or better tools. Tracking MTTR over time shows if maintenance strategies are working.
MTTR applies to many systems, such as factory machines, computer networks, and software. By focusing on MTTR, businesses can boost their efficiency and stay competitive.
[ez-toc]
Calculating MTTR
https://www.youtube.com/watch?v=Bs0G7CpAm-Y
The MTTR formula is:
MTTR = Total Repair Time / Number of Repairs
Source: WorkTrek
This calculation gives the average time it takes to fix an issue. To use this formula, add up all the repair times for a set period. Then divide by the number of repairs done in that time.
For example, if a company had five repairs that took 2, 3, 1, 4, and 5 hours:
Total Repair Time = 15 hours Number of Repairs = 5 MTTR = 15 / 5 = 3 hours
Listen to a Podcast on MTTR
Components of MTTR
MTTR includes several stages in the repair process:
Detection: Identifying that a failure has occurred
Diagnosis: Finding the cause of the problem
Repair: Fixing the issue
Testing: Ensuring the system works correctly
The clock starts when a failure is detected and stops when the system is back online. MTTR doesn't include time spent waiting for parts or technicians.
Illustration: WorkTrek/ Quote: Splunk
Factors that can affect MTTR:
Skill level of maintenance staff
Availability of spare parts
Quality of diagnostic tools
Complexity of the system
Reducing any of these factors can help lower MTTR and improve system reliability.
MTTR vs. Other Metrics
https://www.youtube.com/watch?v=OSnBQraYlkA
MTTR is one of several metrics used to measure system performance. It works alongside other important measures:
MTBF (Mean Time Between Failures): The average time between system failures
MTTF (Mean Time to Failure): The average time until a system fails
Availability: The percentage of time a system is operational
MTTR + MTBF = MTTO (Mean Time to Operations)
This formula shows how MTTR and MTBF work together to measure total downtime. A low MTTR combined with a high MTBF indicates a reliable system with quick repairs.
While MTTR focuses on repair time, MTBF and MTTF look at the frequency of failures. These metrics give a complete picture of system reliability and maintenance effectiveness.
Collecting Performance Data
Good data collection is key for accurate MTTR. Companies need to track:
Start and end times of each repair
Type of equipment or system repaired
Cause of the breakdown
Steps taken to fix the issue
Illustration: WorkTrek/ Quote: Forbes
Using software like a CMMS system to log this info can make data collection more accessible and precise. Training staff on proper data entry is important to ensure correct calculations.
Regular reviews of repair logs can help spot trends and areas for improvement.
Benchmarking Against Industry Standards
Comparing MTTR to industry standards helps businesses gauge their performance. Steps for benchmarking include:
Find reliable sources for industry data
Compare MTTR to similar companies
Look at top performers in the field
Set goals based on these comparisons
Illustration: WorkTrek/ Quote: ReliablePlant
Company size, equipment type, and operating conditions can affect MTTR. When benchmarking, aim to match these factors.
Regular benchmarking can drive continuous improvement in maintenance processes.
Maintenance Strategies to Improve MTTR
Companies can use several key strategies to reduce their Mean Time to Repair (MTTR). These approaches focus on preventing issues, using data to predict problems, and improving maintenance team skills.
Preventive Maintenance
Preventive maintenance helps catch problems early. Fixing small issues before they become big ones can lower MTTR.
Illustration: WorkTrek / Data: Gecko
Regular checks and part replacements are key. For example, a factory might change machine oil every month. This stops breakdowns from happening in the first place.
Keeping good records is also important. Teams can track when parts were last replaced, which helps them better plan future maintenance.
Predictive Maintenance and Analytics
Predictive maintenance uses data to spot problems before they happen. This can significantly cut down MTTR.
Illustration: WorkTrek / Data: Bolt Data
Sensors on machines collect data constantly. Special software analyzes this data to find patterns, which can indicate when a machine might break soon.
For instance, a sensor might notice a motor running hotter than normal. The team can then fix it before it fails completely, saving time and money.
Machine learning helps make these predictions more accurate over time. As the system collects more data, it gets better at spotting issues early.
Maintenance Teams and Training
Well-trained teams can fix problems faster. This directly improves MTTR.
Regular training keeps staff up-to-date on new tech and methods. For example, teams might learn about new diagnostic tools every few months.
Illustration: WorkTrek/ Data: Shortlister
Creating detailed repair guides helps too. These step-by-step instructions make repairs quicker and more consistent.
Encouraging knowledge sharing among team members is vital. Experienced staff can teach newer members tricks they've learned. This spreads skills across the whole team.
Tracking and Responding to Incidents
Effective incident management involves several key steps to minimize downtime and restore services quickly. These include setting up a framework, measuring response times, and finding the root causes of problems.
Incident Management Framework
Illustration: WorkTrek/ Quote: Cyberday
A solid incident management framework helps teams handle issues smoothly. This framework outlines roles, steps, and tools for dealing with problems. It typically includes:
• Incident detection and logging
• Prioritization based on impact
• Escalation to the right team members
• Communication channels for updates
The framework should be clear and easy to follow. Regular drills help teams practice their roles and improve their skills.
Mean Time to Acknowledge and Respond
Quick response is crucial for solving problems fast. Two key metrics track this:
Mean Time to Acknowledge (MTTA): How long it takes to notice an issue
Mean Time to Respond (MTTR): How long before work starts on fixing it
Teams aim to keep these times short. Automated alerts and on-call schedules can help. Tracking these metrics over time shows if a team is getting faster or slower at handling issues.
Root Cause Analysis
After fixing an incident, it's important to find out why it happened. Root cause analysis digs deep into the problem. It looks for the main reason, not just surface symptoms.
Steps in root cause analysis include:
Gather data about the incident
Identify possible causes
Test each cause to find the real one
Suggest ways to prevent similar issues
This process helps stop the same problems from happening again. It also shows patterns that might point to bigger issues in systems or processes.
Improving Customer and User Experience
Reducing MTTR improves customer satisfaction and user experience. Fast problem resolution helps businesses meet service-level agreements and minimize disruption.
Aligning MTTR with User Expectations
Users expect quick issue resolution. Companies should set MTTR goals that match customer needs. Short MTTR targets work for critical systems, while longer targets may suit less vital services.
Illustration: WorkTrek/ Quote: XM Experience Management
Businesses can survey users to understand their expectations. This data helps set realistic MTTR goals. Companies should also educate users on typical resolution times. Clear communication prevents frustration.
Regular MTTR reviews ensure goals stay relevant. As technology changes, so do user needs. Keeping MTTR targets current helps maintain customer happiness.
Communication and Transparency
Illustration: WorkTrek/ Data: Deputy
Open communication during incidents builds trust. Users appreciate updates, even if issues aren't fixed yet. Clear, timely messages show the company cares.
Status pages provide real-time information on service health. They let users check problems without contacting support, saving time for both customers and staff.
Sharing post-mortems after incidents demonstrates accountability. These reports explain what went wrong and how to prevent future issues. They show users that the company learns from mistakes.
Minimizing Business Impact
Fast MTTR reduces downtime costs. It limits lost productivity and revenue. Quick fixes also prevent damage to brand reputation.
To minimize impact, companies can:
Use redundant systems
Create detailed incident response plans
Train staff on fast problem-solving
Prioritizing high-impact issues helps, too. Fixing problems that affect many users first improves overall satisfaction.
Companies should track downtime costs. This data shows the value of reducing MTTR. It can justify investments in better tools or training.

Compliance & Control
What is Mean Time to Failure – MTTF
MTTF stands for Mean Time to Failure. Engineers and manufacturers use it as a key measure of product reliability. It tells us how long a product or system will likely work before breaking down.
This metric helps companies plan maintenance and set customer expectations. A higher MTTF usually means a more reliable product. For example, a light bulb with an MTTF of 1,000 hours is expected to last longer than one with an MTTF of 500 hours.
MTTF applies to items that can't be fixed once they fail.
A measure called Mean Time Between Failures (MTBF) is used instead for things that can be repaired. Both help businesses make better products and keep customers happy.
Calculating MTTF
To find MTTF, divide the total hours of operation by the number of failures. The formula is:
MTTF = Total Operating Hours / Number of Failures
Source: WorkTrek
For example, if 100 light bulbs run for 1000 hours total and 10 fail:
MTTF = 1000 hours / 10 failures = 100 hours
This means each bulb is expected to last about 100 hours on average.
Testing many units over time gives more accurate MTTF values. Longer test periods often lead to better estimates.
MTTF vs. MTBF
MTTF and MTBF are similar but have key differences:
MTTF: Used for non-repairable items
MTBF: Used for repairable systems
MTBF includes repair time, while MTTF does not. MTBF is often higher than MTTF for similar items.
Here's a comparison chart:
Source: WorkTrek
Both metrics help predict reliability, but they're used for different types of systems.
Listen to a Podcast on MTTF
Application in Industries
MTTF plays a crucial role in various industries. It helps organizations optimize their operations and minimize disruptions.
Manufacturing and Production
Many factories use MTTF to schedule planned maintenance. This reduces unexpected downtime on production lines and helps keep productivity high.
Some companies use MTTF to decide when to replace old equipment. They compare the MTTF of aging machines to newer models, which helps them make smart upgrades.
MTTF also guides asset management strategies. It helps firms decide which machines need the most attention, ensuring critical assets get proper care.
Software and DevOps
MTTF is a useful DevOps metric in software. It measures how long systems run without crashes or errors.
Teams use MTTF to track system stability over time. A rising MTTF often means fewer bugs and better code quality.
MTTF helps with incident management, too. It shows how often significant issues pop up. This data can guide efforts to improve system reliability.
Some teams use tools like Jira Service Management to track MTTF. These tools help spot trends and set goals for system uptime.
MTTF can also highlight areas that need more testing or redesign. This helps teams focus their efforts where they'll have the most significant impact.
Components of MTTF
MTTF depends on the quality and durability of individual parts. Reliable components and proper maintenance are key to maximizing system uptime.
Importance of Reliable Components
Critical components like engines, fan belts, and wheels impact overall MTTF. High-quality parts last longer and break down less often, reducing repair costs and downtime.
Designers focus on making durable components. They use strong materials and smart designs to help parts withstand wear and tear.
Reliable components lead to better system performance and, in many cases, boost safety. Sturdy brakes on a car can prevent accidents.
Lifecycle of Components
Every part has an average lifespan. Some may last for years, while others need frequent replacement. Knowing these lifespans helps plan maintenance.
Regular checks can catch issues early, preventing sudden failures. Replacing parts before they break is called preventive maintenance.
Some components wear out faster than others. Fan belts and tires often need replacement sooner than engines. Tracking part lifecycles helps predict when to order replacements.
Proper care can extend component life. This might include regular cleaning or lubrication. Following manufacturer guidelines is important for maximizing part longevity.
Maintenance Strategies
Effective maintenance strategies help organizations improve equipment reliability and reduce downtime. These approaches focus on preventing failures and tracking performance metrics.
Proactive vs Reactive Maintenance
Proactive maintenance aims to prevent equipment failures before they happen. It includes scheduled inspections, part replacements, and upgrades. This approach can extend asset lifespans and cut repair costs.
Reactive maintenance only fixes equipment after it breaks down. While it may seem cheaper upfront, it often leads to more expensive repairs and longer downtimes.
Source: WorkTrek
Most companies use a mix of both strategies. They focus proactive efforts on critical assets while handling less important items reactively.
Maintenance Metrics and KPIs
Maintenance teams use key performance indicators (KPIs) to measure their effectiveness. Common metrics include:
Mean Time Between Failures (MTBF)
Mean Time To Repair (MTTR)
Overall Equipment Effectiveness (OEE)
Source: WorkTrek
These KPIs help track equipment reliability, repair speed, and production efficiency. Teams can use them to spot trends and make data-driven decisions.
Benchmarking against industry standards lets organizations see how they compare to peers. This can reveal areas for improvement in their maintenance programs.
CMMS software often helps collect and analyze these metrics automatically. This makes it easier for teams to monitor performance and adjust their strategies as needed.
MTTF and Business Impact
MTTF affects a company's bottom line and customer relationships. It plays a key role in managing downtime and costs.
Implications on Customer Satisfaction
MTTF directly impacts customer satisfaction. Frequent failures lead to unhappy customers and lost business. Companies with high MTTF have fewer outages and more reliable products.
Illustration: WorkTrek / Quote: Hubspot
Customers expect products to work without issues. Long periods between failures build trust and loyalty. This leads to positive reviews and word-of-mouth referrals.
On the flip side, low MTTF causes frustration. Customers may switch to competitors if they face too many problems. Businesses need to track MTTF as a key metric for customer happiness.
Cost Implications
MTTF has big effects on a company's costs. Higher MTTF means less money spent on repairs and replacements. It also reduces the need for customer support staff.
Low MTTF leads to more frequent repairs, which increases labor and parts costs and can result in costly downtime for critical systems.
Here's a simple breakdown of MTTF cost impacts:
High MTTF: Lower repair costs, less downtime
Low MTTF: Higher repair costs, more downtime
Smart companies invest in improving MTTF. This often leads to long-term cost savings. It's a key part of running a cost-effective business.
Enhancing MTTF
Companies can take steps to improve their products' Mean Time To Failure. This leads to better reliability and customer satisfaction.
Root Cause Analysis
Illustration: WorkTrek / Quote: Harvard Business School Online
Root cause analysis helps find the source of failures. Engineers look at broken products to spot weak points. They might use tools like fault tree analysis or fishbone diagrams.
Testing plays a significant role, too.
Products go through stress tests to find breaking points. This data helps make better designs.
Engineers also check how people use products in real life. Sometimes, customers use items in unexpected ways. This info leads to more robust designs.
Investment in Quality and Design
Investing in quality pays off. Better materials often last longer, and stronger parts can handle more wear and tear.
Smart design choices boost reliability, too. Simple designs with fewer parts often break less, and backup systems can keep products working even if one part fails.
Companies can also focus on making products easy to fix. This might mean using standard parts or making repair guides. When fixes are simple, products stay helpful longer.
Training workers well is key for quality. Skilled staff catch more issues before products leave the factory.
Modern Tools and Technologies
New tech improves MTTF tracking and prediction. Sensors on production lines gather real-time data, helping to spot issues before failures occur.
AI and machine learning analyze patterns to predict breakdowns. Digital twins simulate equipment to test different scenarios.
Maintenance teams use mobile apps to log repairs quickly. Cloud systems store vast amounts of reliable data.
Advanced diagnostics pinpoint root causes faster. This cuts downtime and boosts overall MTTF.
Automated monitoring alerts staff to potential problems. It can trigger planned maintenance before critical failures.
Make your work easier.
Try for free.
Book a demo